
Working with any popular programming framework today means using an object-relational mapping (ORM) library like Rails’ ActiveRecord
to interact with the database. ORM systems are a definite plus for developer productivity and general happiness.They also allow a programmer to get by with a little bit less knowledge (sometimes a whole lot less) about what’s happening in between their code and the database. But that convenience comes with some pitfalls, including the common N+1 query problem. What does that mean? Read on to find out!
Working with an ORM
When we use an ORM library to load what our code calls an object (and the database calls a row), providing the unique identifier (primary key) is sufficient to generate and execute the Structured Query Language (SQL) needed to load our object data into memory. Similarly, we can update attributes on the object and then simply save it. Once again, SQL is generated automatically by the ORM to save the changes to the database.
This is straightforward when working with a single row of data. But there are lots of places in our application where we want to show data in lists, tables, graphs, etc. If we were writing that SQL by hand, we’d write a SELECT clause to specify the columns we want and a WHERE clause that matches all the data we want to see. In this way, we’d grab the entire table’s worth of data in one query. This batch retrieval is lot more efficient than querying the rows one at a time using $N$ queries for $N$ rows.
Batch retrieval and associations
ORM systems have a couple of features to support batch retrieval. The first is accessor methods that allow the programmer to specify the conditions of a WHERE clause and return multiple objects in an array, rather than just a single object. This feature makes it easy to find all rows that, for example, match a user-specified search term. The second (more complex) feature is associations. An association is a relationship (or, in database terms, a relation) between two types of data.
A classic example of an association, which is used in the Rails Tutorial sample app, is users -> microposts -> attachments. The Rails sample app requires all users to log in. Each user is represented in the database as a row in the users table.
Once logged in, users can submit microposts (think of a micropost as a tweet). Each micropost can have zero or more attachments (such as images). In database terms, the relationship between users and microposts is one-to-many, and between microposts and attachments is also one-to-many. If an attachment could be shared by multiple microposts, then the relation would be many-to-many.
Loading data for display
Let’s take a look at how the ORM interacts with this schema in a common scenario: showing the microposts feed for a user. Consider a controller that retrieves a page of microposts for this user:
@user.microposts.paginate(page: params[:page])
The ORM is smart enough to fetch one page of microposts in one batch, making the this operation simple and efficient… right? Not necessarily.
When we look under the covers, there’s a problem!
Understanding view-SQL interactions
To show you what’s really going on, I’m going to use a tool that I helped build called AppMap. It’s available as a free, open source AppMap extension for VSCode. AppMap for Visual Studio Code is a self-contained extension that automatically records and diagrams software behavior by executing test cases. You can use the AppMap extension to walk through an automatically generated dependency map and execution trace of any Ruby app right in your code editor.
Here’s part of the AppMap Trace view that shows the microposts being loaded:
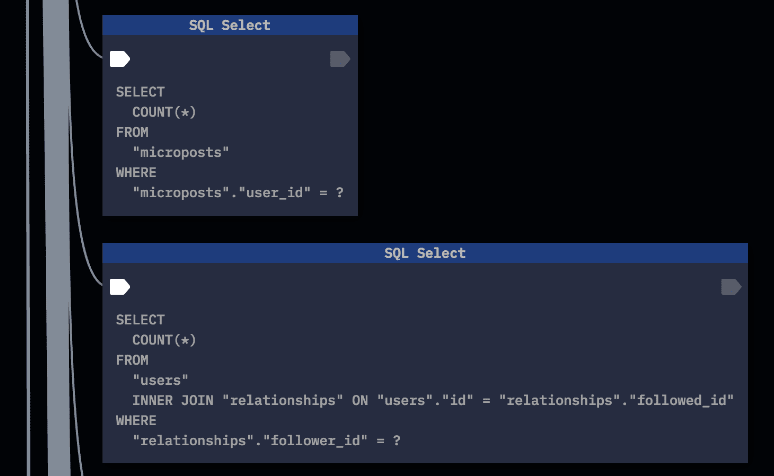
So far, so good. The problem is that the rest of the trace looks like this: a long sequence of repeated, additional SQL queries as the micropost associated data is loaded.
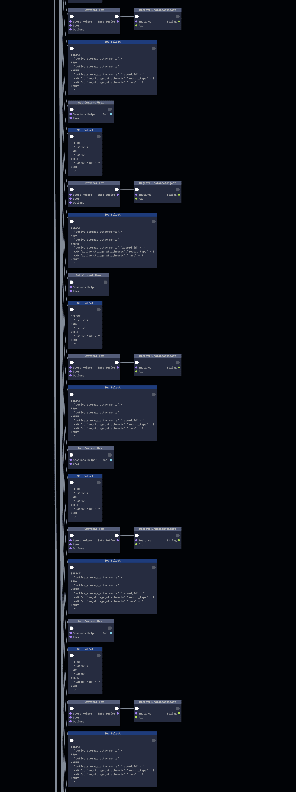
This anti-pattern is called an N+1 query problem.
An AppMap is a great tool for figuring out when you have this problem in your code. In fact, it’s pretty helpful for finding all kinds of code logic, behavior, and SQL query problems. But in this case, I’d like to go a level deeper and ask if there is an even more fundamental root cause. Having thought about this, I believe that they way that web frameworks and ORMs encourage developers to render ORM objects directly in the view layer is creating a rather significant problem.
What happens is this: view templates are full of loops and iterations. And when a template loops over an ORM object, the object will happily make query after query to fetch the requested data. The result is a functional but slow-performing page.
Solution - Use POROs in the view
“PORO” is a term borrowed from Java, meaning “Plain old Ruby object”. I’m a pretty big fan of the Ruby Struct, which provides “a convenient way to bundle a number of attributes together, using accessor methods, without having to write an explicit class”. When you provide a PORO to a view template (such as a Rails view), the developer is required to pre-load the PORO with the of data and associations that’s needed by the view. If the view tries to access additional data … “whoops”, there’s going to be an error such as a NoMethodError.
So, supposed I want to render a list of posts and attachments. I can do it something like this:
AttachmentListItem = Struct.new(:url)
PostListItem = Struct.new(:body, :username, :attachments)
def user_posts(user_id)
@user.posts[user_id: user_id]
.eager(:user, :attachments)
.map do |post|
attachments = post.attachments.map do |attachment|
AttachmentListItem.new(attachment.url)
end
PostListItem.new(post.body, post.user.name, attachments)
end
end
Note: eager is a feature of the Sequel library. For ActiveRecord, use includes.
With this code as written, I can now review the query behavior and I will know that if a future programmer changes the view template to fetch new or different data, she won’t accidentally introduce a sneaky performance problem. These types of simple design changes, for reliability and maintainability, aren’t harder to code or harder to test, and they can pay off handsomely in predictable behavior.
I hope you’ve found this post helpful! To inspect the behavior of your own code and learn more about this and other code patterns and anti-patterns, check out the AppMap extension for VSCode.
Originally posted on Dev.to