
Start using Navie today!
Navie, the AI Software Architect is free and available to use immediately as part of the AppMap extension for your favorite code editor.
Get Navie for Visual Studio Code or JetBrains
Introduction
Like the 24 Hours of Le Mans, SWE Bench is an AI coding challenge that is as much about efficiency and stability as it is about raw power or ability to spend money. The AppMap “Navie” AI coding assistant posted 14.6% on the SWE Bench AI coding benchmark, ahead of Amazon Q and 8 other tools. SWE Bench is considered to be the most difficult of the well-known coding benchmarks. We were able to complete this monumental task in under 4 hours at the lowest cost of operation - between 5% and 30% of the cost of other solvers.
In this post, we’ll describe the methodology that Navie used to solve benchmark issues, and why Navie is the most cost-effective approach. We’ll describe our results in more detail, and talk about what we learned.
What is the SWE Bench?
SWE Bench is a benchmark and dataset that assesses AI language models and agents on their ability to solve real-world software engineering issues. The benchmark provides a diverse set of codebase problems that are verifiable using in-repo unit tests. The SWE Bench database is made up of 2,294 issues from 12 popular Python repositories, along with their human-coded solutions and test cases.
SWE Bench is an open benchmark. Anyone can submit a solution using the open source SWE Bench Experiments project on GitHub. To be accepted, all 2294 questions must be attempted. For an easier challenge, there is also a SWE Bench Lite benchmark consisting of only 300 questions. We focused Navie on the full SWE Bench database, because it best represents the challenges that working software engineers face in real life.
About AppMap Navie
Navie is an open source AI software architect from AppMap. Navie is part of the AppMap code editor extension for VSCode and JetBrains, and was first made generally available in May of 2024. You can install and use Navie today through the IDE marketplaces. Navie is open source, and there’s no waiting list for access!
The Navie benchmark code and the Navie component of the AppMap extension use the same AI logic. Navie in the IDE is an interactive chat UI. For SWE Bench, Navie has been adapted to use a fully “hands off”, automated approach.
Navie Architecture
The term “agent” is used to describe an AI program that is given a set of tools, and freedom to choose and use them. Navie is not agentic in this sense; the Navie algorithm is deterministic, progressing through stages of context retrieval, planning, code generation, lint repair, and test repair. Following this defined procedure makes Navie cost-effective, fast, and predictable to run.
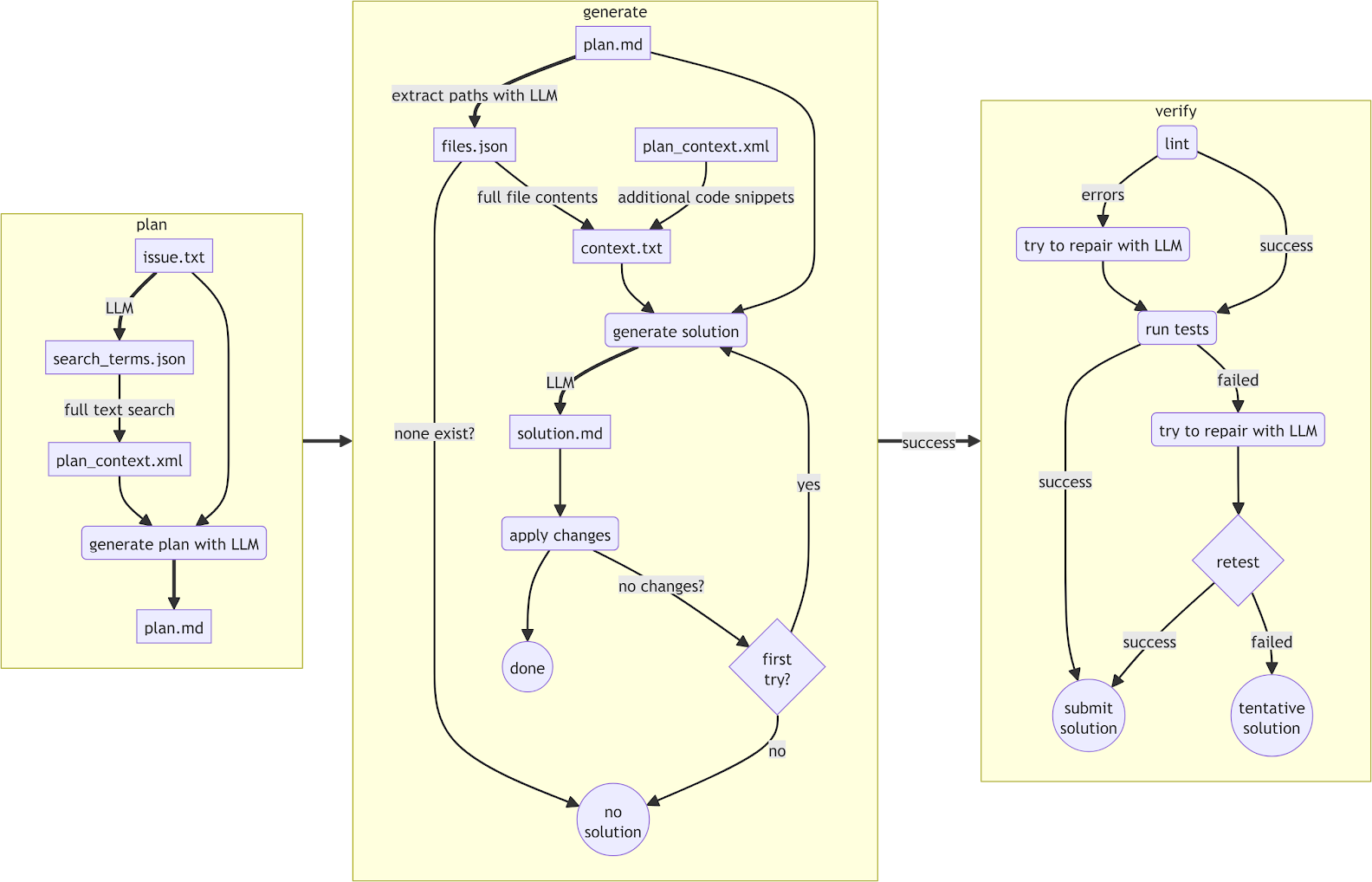
The operation of Navie is divided into 3 high level phases:
- plan Given the issue text, retrieve the relevant code context. Context retrieval is a local operation that does not involve the LLM, and is therefore fast, predictable, and efficient. Next, the issue text and selected context are sent to the LLM to generate a plan.md file, which is essentially a design for how the issue will be solved.
- generate Navie inspects the plan to determine which files will be modified. These files are provided to the LLM along with the plan.md file and the selected context to produce a specific set of code changes. Each planned code change consists of two code blocks: “existing” code to find, and a code “update” to apply.
- validate Once the code changes are applied, Navie runs a linter and attempts to automatically repair any errors, using the generate/apply mechanism to make code changes. Navie also runs tests in the repository, and attempts to fix any failures that occur.
A “generated” solution can therefore be assigned a “quality” score. In increasing quality:
- apply The code patch was successfully applied
- lint_repair Additionally, the code does not have lint errors.
- posttest_failed Additionally, tests were run but some tests failed and could not be fixed.
- posttest Additionally, tests ran and passed.
The entire process is repeated up to three times with a maximum token limit of 128k for any completion, although the actual token count in practice was usually far less. If after three attempts no solution is found that passes the tests, the solution with the highest “quality” is chosen.
The average number of outer loop iterations was 1.4. Only 8.8% of instances required 3 iterations to generate a solution. 6.0% of the successful solutions were obtained from a 3rd iteration. Additional iterations may have yielded additional positive results.
Context retrieval
As mentioned in the introduction, cost and time efficiency is a major feature of Navie. LLM-independent operation is also important, so that the most efficient LLM backend can be used for a particular codebase or problem. Therefore, Navie performs its own context lookup and relevance determination using 100% client-side code. The entire codebase is indexed in seconds, and matched against the user’s question. In the benchmark, the issue text is the question. Navie can be configured to use the LLM to transform the question into a more optimal set of search terms; however this feature was not enabled for the SWE Bench runs. You can review the cost impact of local context lookup in the comparative data plots presented in the Cost and Token Analysis section. To recap:
- Navie does not use embeddings.
- Navie does not rely on a pre-built index of the code; either local or remote.
- Navie performs local context lookup, with runtime in milliseconds to seconds (depending on codebase size).
Benchmark scaling and auditability
To design and tune an effective solver, it’s important to be able to quickly and effectively evaluate different ideas for improving the software. Our goal was to be able to perform a full run of the SWE Bench in less than 5 hours, and to perform a SWE Bench Lite run in less than 1 hour. It’s also essential to know exactly what code is running for each attempt, and what the state of the benchmark machine is for each run.
We achieved our performance and auditability goals by running Navie in GitHub Actions. Using a GitHub Actions workflow for each run allowed us to parallelize the benchmark instances, and it also provided an audit trail of the entire lifecycle. Each solution that was generated by Navie comes from a specific GitHub Actions run, which in turn is linked to a specific commit SHA of the solver code.
Benchmark methodology
To run the Navie benchmark and evaluation, we forked the SWE Bench project on GitHub and customized it. Our fork of SWE Bench is available at getappmap/SWE-Bench.
Navie used GPT-4o as the LLM. The instances were split into a GitHub Actions matrix run, and each worker node was assigned a set of problem instances. These instances were solved within a Git checkout of the target project and an installed Conda environment, as specified by the SWE Bench project. Navie was not allowed to make changes to project dependency configuration, setup scripts, or test cases. This ensured that Navie’s generated solution would not interfere with the evaluation procedure.
Each solution attempt generated by Navie was tested for acceptance using the evaluation procedure provided by the SWE Bench project. Of course, the code of the acceptance tests that are used for evaluation were not available to Navie for the purposes of generating solutions.
| Benchmark name | Benchmark total instances | Number generated | Percent generated | Number resolved | Percent resolved |
|---|---|---|---|---|---|
| SWE Bench | 2294 | 2246 | 97.91% | 335 | 14.60% |
| SWE Bench Lite | 300 | 300 | 100% | 65 | 21.67% |
Navie correctly resolved 331 of the 2294 SWE Bench instances, or 14.6%. We also ran Navie on the SWE Bench Lite benchmark, scoring 65 of 300 issues or 21.67%. The only difference between Navie on the full and Lite benchmarks is that on the Lite benchmark, Navie was instructed via LLM prompt to only modify one file.
Navie on SWE Bench

Navie on SWE Bench Lite

Cost and Token Analysis
In addition to calculating the solution rate, we also collected data on AI API Costs for each solution and those are reported below.
Navie’s “wall time” to run the full SWE Bench benchmark was about 4 hours. Navie collected up to 8k tokens for the combined issue statement and context, via local retrieval as described earlier.
Subsequent steps of the LLM allowed up to the full max of the LLM (128k) context window, but generally only used between 8k and 32k. A few cases of overflow occurred when a failed test had a giant stack trace in the error report.
Average Prompt Tokens per issue was 171,806, and the Average Total Completion Tokens was 4,993, yielding an Average Total Tokens of 176,799 per problem. Average Cost per benchmark problem on GPT-4o was $0.88.
Dollar Cost SWE Bench Full

* implied cost from blog post indicating <~2M average token count per inference using GPT4o list pricing
Dollar Cost SWE Bench Lite

Token Cost SWE Bench Full

AppMap Navie has the lowest reported cost per instance of all reported benchmark solvers. For example, CodeR reports a per-instance cost of $3.09 on SWE Bench Lite. Factory Code Droid, which reported using an average of less than 2 million tokens per issue, but up to 13M maximum, can be projected to cost between $20 and $130 per instance using GPT-4o.
What is next for benchmarking AppMap Navie?
We are grateful to the SWE Bench team for creating a project that allowed us to highlight AppMap Navie’s capabilities and strengths. Both Navie itself and our fork of SWE Bench are open source, and we will continue to improve on Navie’s benchmark capabilities.
One limitation of SWE Bench is that many of the issues are debugging style tasks on Python software libraries. Because AppMap Navie has detailed knowledge of the application’s runtime behavior, it can provide much higher quality of AI assisted changes for more complex applications, and it is used in practice this way at many organizations.
We are working on extending SWE Bench to create a new benchmark of full-stack web applications and web services, including projects such as Django “Oscar” and Java “Waltz”. Solving issues in these types of applications requires understanding of API interactions, database interactions, dependency injection, and other runtime behaviors. If you have an open source “full stack” application, database-backed service, or microservice monorepo that you would like to add to the AppMap SWE Bench challenge extension, please let us know via GitHub or consider joining our open source community.
What’s coming next in Navie
In the near term we will continue to deliver on our roadmap, including:
- Bringing AI agent capabilities into the VSCode and JetBrains extensions.
- Improving the depth and breadth of runtime analysis in the code editor to support AI coding.
- Enabling organizations to run and use Navie in automated environments such as CI.
AppMap believes in Open Source, Transparency, Security and Privacy
Owing to AppMap’s unique offline architecture, AppMap Navie has been adopted by developers around the world working in data-sensitive environments such as government and financial services. We will continue to deliver on our open-source commitment with transparent data and IP protections that are user controlled.
The values of openness, user self-determination, data control, and privacy are foundational principles for AppMap. These values are even more crucial now as AppMap joins the ranks of AI software coders.
AppMap’s vision for the future of AI coding
Our work has always been grounded in one belief: better data facilitates better decision making.
In the coding workflow, whether the coder is a human or an AI, depth of information and experience is the key to better planning and execution. Today, much of the valuable information that AIs need to become better software developers remains hidden. Our plan is to continue finding and surfacing this information, and making it available to AIs for code design, planning, implementation, and verification.
Areas we are exploring include:
- Building models of code behavior from combinations of static and runtime data, and using these models to both plan and validate AI-implemented software.
- Fine-tuning and training models using runtime data and information about architectural design.
- Incorporating knowledge of system architecture, APIs, and data schemas into AI models and RAG augmentation.
- Model-based risk assessment and categorization of AI-generated code.
These enhancements will enable AI software assistants to grow their capabilities - improving from the “coding assistants” of today, to the “software developer” and “architect” assistants of tomorrow.
To learn more about AppMap and Navie, contact us at info@appmap.io.
For a hands-on experience with AppMap Navie install AppMap for Visual Studio Code or JetBrains code editors.
For all other requests complete this form and an AppMap representative will get right back to you. Alternatively, feel free to email us at sales@appmap.io.