
AppMap is an open source framework that developers can use to record, analyze, and optimize end-to-end code and data flows. The framework provides client agents for Ruby, Java and Python (early access) that record running code and generate JSON files called AppMap Diagrams. Users can view and analyze these diagrams locally using the AppMap extension for VS Code, and also push AppMap Data to AppMap Cloud for analytics, sharing, discussion etc.
The AppMap server is built to ingest and process large AppMap JSON files. Our stack is vanilla Rails and PostgreSQL. Naturally, we use the powerful JSONB data type to store the JSON data in the database. In the initial development period of the AppMap server, AppMap files typically ranged from a few KB up to a few hundred KB. But before long, AppMap server users started to record some very large apps, including monolithic Java and Ruby repos with up to 1 million lines of code. As hundreds, and then thousands of JSON files were generated from these large repos and pushed into the AppMap server, our server became stressed and we had to dig in and optimize. In this post, I’m describing some of the ways that we scaled up our architecture to handle these large JSON files. So, without further ado, here are four ways to accelerate JSON processing with Rails and PostgreSQL.
1. Skip Rails JSON parsing on POST
When AppMap Data is received by the AppMap server, we want to get it into PostgreSQL as fast as possible. When Rails receives an HTTP request with content type application/json, it parses the request JSON into Ruby objects and then passes this data, as params, to the controller. Since all we want to do is insert the data into PostgreSQL, and PostgreSQL can parse the JSON itself, we don’t need Rails to do any parsing. So, we disable Rails JSON parsing behavior by sending content type multipart/mixed instead of application/json. In this way, we minimize the amount of request processing that’s performed in the application tier. The JSON data is loaded efficiently into PostgreSQL, without having to sacrifice all the benefits provided by the Rails framework.
Here’s an example of our Go client code sending multipart/mixed
2. Pay attention to algorithm design
With a few hundred KB of data, most simple algorithms will perform about the same. But as the data grows to dozens of MB and beyond, algorithm design becomes very important. We discovered that one of our AppMap post-processing algorithms had an O(n²) running time. We were able to rewrite this algorithm as O(n). Here’s what that difference looks like in a graph of time and memory vs data size:
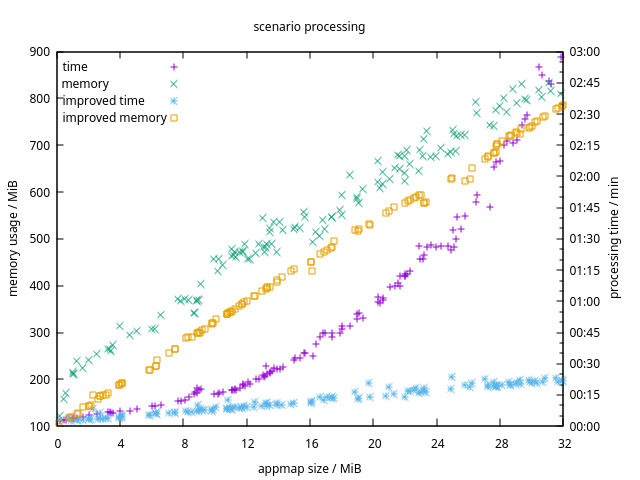
Keep those computer science fundamentals in mind, especially as the data gets bigger! There’s no point in trying to optimize a poor algorithm by writing faster code. This algorithm performs just fine in plain Ruby now that it’s inherently efficient. It’s doing in 22 seconds what used to take 3 minutes.
3. Use indexes and generated columns to speed up access to big JSON objects
The beauty of JSONB is that you don’t have to choose between the flexibility of “schema less” JSON and the power of SQL and relations.
As I describe earlier, the AppMap Data is written directly into the database by the controller. Later, we want to make this data easily to query and retrieve. Two PostgreSQL techniques help us to make these operations efficient.
First, a sometimes we want to reach into AppMap Data and search by a particular field, such as “labels” or “metadata.name”. We can make this this efficient by adding indexes on the JSONB data.
Second, there are situations where we want to retrieve a subset of the JSONB data, and we don’t want to have to parse many megabytes of JSONB data just to pluck out a few fields. So, when the data is loaded, we copy (or denormalize) some of the JSON data into columns in the same record. Generated columns make this fast and efficient, and ensure that the denormalized data is always up to date.
For more details on these techniques, check out my companion post Effective SQL - Indexing and denormalizing JSONB.
4. Process JSONB in the database using SQL functions
Databases aren’t just for storing data, they are great for processing it as well. In the case of JSONB, PostgreSQL provides a full range of functions and operators that you can use to filter and transform data before you SELECT it out. By processing data in the database, you can use each tool for what it does best: PostgreSQL for data crunching, Ruby for gluing the front-end to the back-end. Here are some examples of data operations that we perform entirely in the database:
- Finding all AppMap Diagrams that contain a particular package, class, or function.
- Building a package and class hierarchy of all the code used in multiple AppMap Diagrams.
- Building a dependency map of packages and classes across multiple AppMap Diagrams.
By doing these computations in the database, we operate efficiently on the data very close to the storage, and we don’t transmit unnecessary data from the database to the application tier.
Well, that’s our list. I hope you find something helpful in here! If you have your own JSON optimization to share, please tell us about it in the comments.
P.S. Most of the optimizations described in this post were designed and developed by our long-time wizard, and friend, Rafał Rzepecki. Thanks, Rafał!
Honorable mention
As a bonus, here are a couple of smaller tips!
Limit the size of SQL log messages
By default, the Rails framework logs all the SQL statements. When the application is inserting large JSON files into the database, it’s not helpful to see megabytes of SQL INSERT logged to the console. So we created this Sequel extension which truncates the log messages:
# frozen_string_literal: true
# Sequel database extension to truncate too long log entries.
#
# SQL statements longer than +sql_log_maxlen+ will get ellipsized in the logs.
module TruncatedLogging
DEFAULT_SQL_LOG_MAXLEN = 2048
private_constant :DEFAULT_SQL_LOG_MAXLEN
attr_writer :sql_log_maxlen
def sql_log_maxlen
@sql_log_maxlen ||= DEFAULT_SQL_LOG_MAXLEN
end
def log_connection_yield(sql, conn, args = nil)
sql = sql[0...(sql_log_maxlen - 3)] + '...' if sql.length > sql_log_maxlen
super(sql, conn, args)
end
end
Sequel::Database.register_extension(:truncated_logging, TruncatedLogging)
Skip ActiveSupport::JSON when generating JSON with Sequel
ActiveSupport::JSON detects dates and times using a regexp, and parses date values into Ruby objects. We don’t use this functionality, so it’s disabled with another Sequel extension:
# config/application.rb
...
config.sequel.after_connect = proc do
Sequel::Model.db.extension :truncated_logging
Sequel.extension :core_to_json
end
...
# frozen_string_literal: true
# lib/sequel/extensions/core_to_json.rb
# ActiveSupport adds some pure ruby manipulation to #to_json
# which isn't useful here and hurt performance. Use JSON.generate
# directly to bypass it.
def Sequel.object_to_json(obj, *args, &block)
JSON.generate obj, *args, &block
end
Originally posted on Dev.to